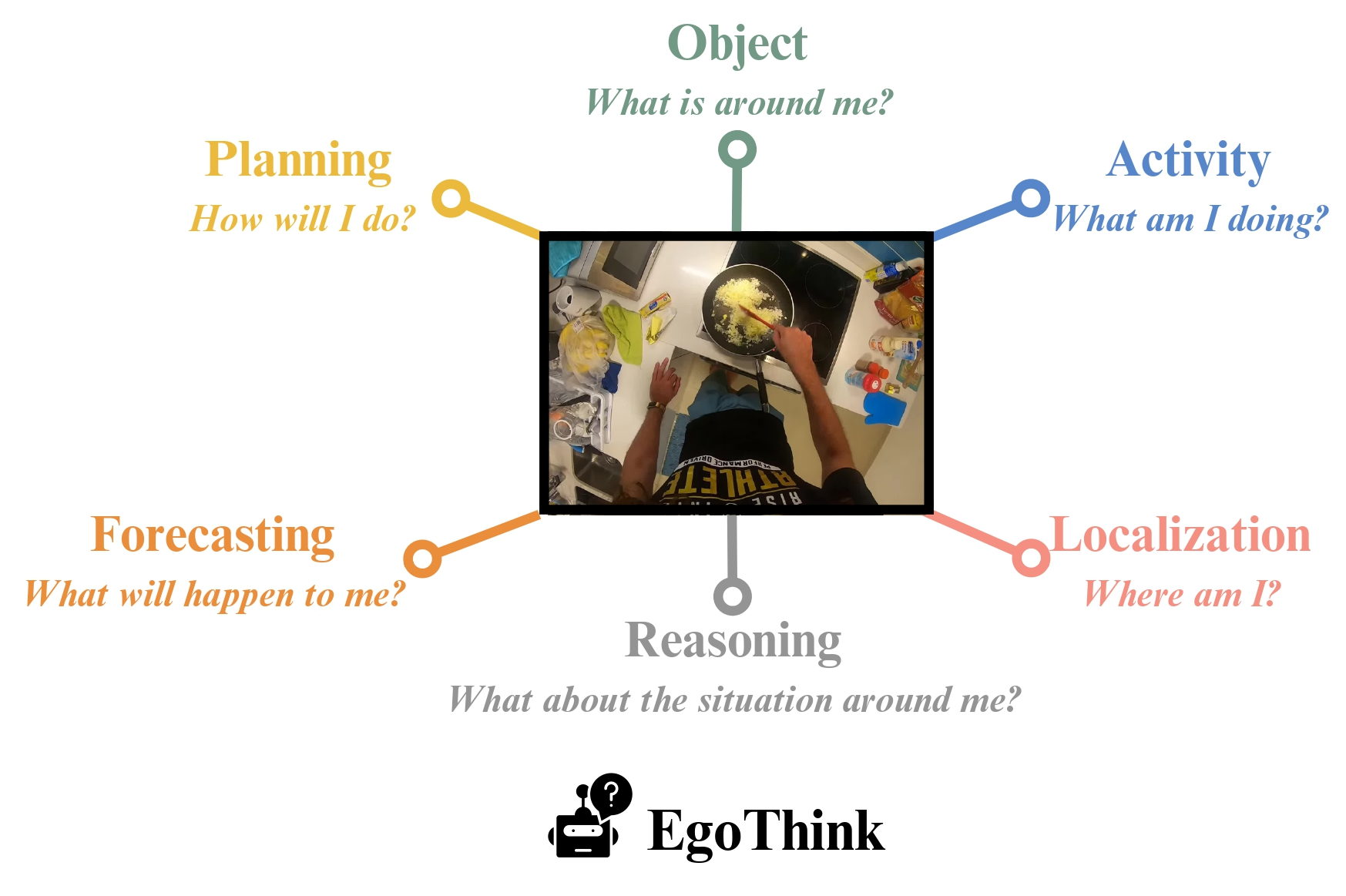
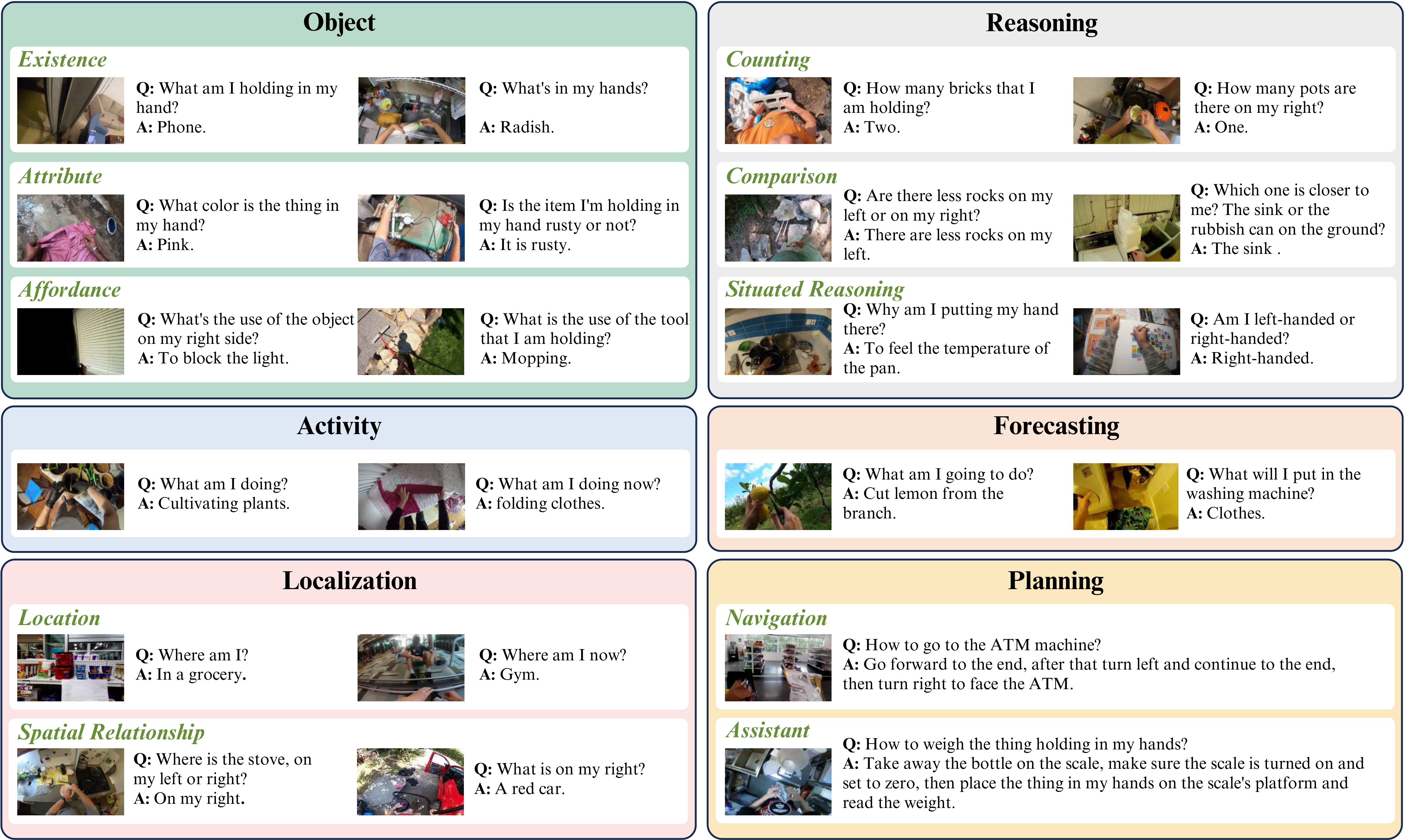
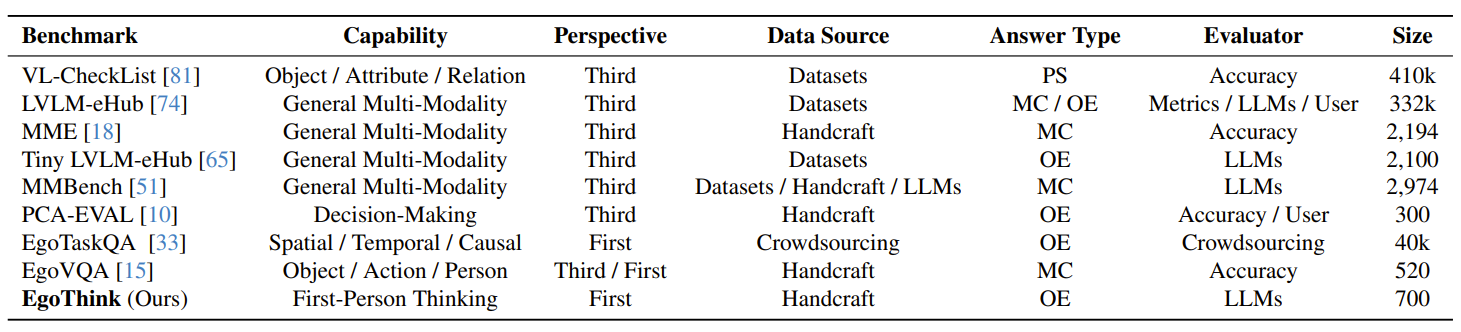

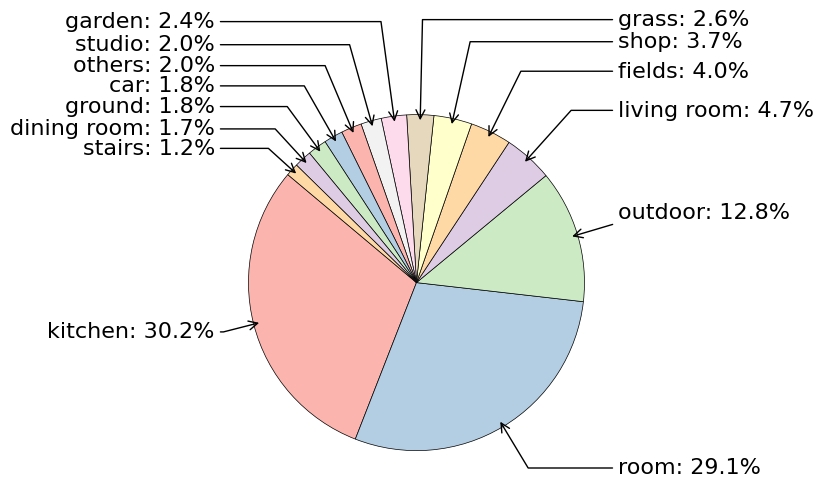
Evaluating open-ended model generations is a non-trivial problem. To address this, we propose using GPT-4 as an automatic evaluator to better measure the generated answers. We continuously update the results of recent VLMs to ensure the effectiveness of EgoThink. Feel free to contribute to the performance of your model by adding it to our index.html; we will review and merge it accordingly.
| Reset | Average | Exist | Attr | Afford | Activity | Loc | Spatial | Count | Compar | Situtaed | Forecasting | Nav | Assist |
| GPT-4V(ision) | 65.5 | 62.0 | 82.0 | 58.0 | 59.5 | 86.0 | 62.0 | 42.0 | 48.0 | 83.0 | 55.0 | 64.0 | 84.0 |
| OpenFlamingo-7B | 27.2 | 16.0 | 55.0 | 37.0 | 15.0 | 34.0 | 34.0 | 21.0 | 40.0 | 21.0 | 31.0 | 11.0 | 11.0 |
| BLIP-2-6.7B | 28.1 | 49.0 | 29.0 | 39.0 | 33.5 | 60.0 | 31.0 | 3.0 | 21.0 | 33.0 | 25.0 | 8.0 | 6.0 |
| LLaVA-1.5-7B | 39.0 | 33.0 | 47.0 | 54.0 | 35.5 | 35.0 | 49.0 | 20.0 | 47.0 | 37.0 | 27.0 | 29.0 | 54.0 |
| MiniGPT-4-7B | 40.6 | 50.0 | 56.0 | 46.0 | 39.0 | 55.0 | 49.0 | 14.0 | 48.0 | 31.0 | 41.5 | 14.0 | 44.0 |
| InstructBLIP-7B | 42.4 | 50.0 | 33.0 | 45.0 | 47.5 | 77.0 | 38.0 | 18.0 | 43.0 | 67.0 | 40.5 | 19.0 | 31.0 |
| LLaMA-Adapter-7B | 42.5 | 37.0 | 60.0 | 46.0 | 34.5 | 48.0 | 51.0 | 29.0 | 39.0 | 25.0 | 41.5 | 42.0 | 57.0 |
| Otter-I-7B | 45.3 | 48.0 | 56.0 | 39.0 | 44.0 | 60.0 | 44.0 | 39.0 | 48.0 | 42.0 | 38.0 | 31.0 | 55.0 |
| PandaGPT-7B | 46.2 | 40.0 | 56.0 | 41.0 | 37.0 | 61.0 | 52.0 | 19.0 | 52.0 | 53.0 | 43.0 | 39.0 | 61.0 |
| mPLUG-owl-7B | 48.8 | 56.0 | 58.0 | 47.0 | 53.0 | 60.0 | 53.0 | 25.0 | 49.0 | 44.0 | 49.5 | 33.0 | 58.0 |
| LLaVA-7B | 49.6 | 63.0 | 58.0 | 50.0 | 47.0 | 81.0 | 45.0 | 24.0 | 36.0 | 47.0 | 49.5 | 35.0 | 60.0 |
| InstructBLIP-13B | 42.8 | 52.0 | 55.0 | 49.0 | 54.0 | 63.0 | 49.0 | 11.0 | 33.0 | 59.0 | 44.0 | 19.0 | 25.0 |
| PandaGPT-13B | 43.1 | 35.0 | 52.0 | 41.0 | 40.5 | 68.0 | 31.0 | 32.0 | 40.0 | 47.0 | 45.5 | 16.0 | 69.0 |
| LLaVA-13B-Vicuna | 46.4 | 54.0 | 62.0 | 52.0 | 46.0 | 53.0 | 46.0 | 26.0 | 44.0 | 29.0 | 44.0 | 35.0 | 66.0 |
| BLIP-2-11B | 49.6 | 52.0 | 62.0 | 41.0 | 49.5 | 90.0 | 66.0 | 25.0 | 50.0 | 70.0 | 48.0 | 18.0 | 24.0 |
| InstructBLIP-11B | 51.1 | 74.0 | 68.0 | 48.0 | 49.5 | 86.0 | 52.0 | 32.0 | 49.0 | 73.0 | 53.0 | 16.0 | 17.0 |
| LLaVA-13B-Llama2 | 55.1 | 65.0 | 61.0 | 45.0 | 56.0 | 77.0 | 53.0 | 34.0 | 34.0 | 66.0 | 50.5 | 49.0 | 71.0 |
| LLaVA-1.5-13B | 55.3 | 66.0 | 55.0 | 51.0 | 55.0 | 82.0 | 57.0 | 32.0 | 56.0 | 67.0 | 48.5 | 39.0 | 55.0 |
Table 4: Combined single-answer grading scores on zero-shot setups for various dimensions. The bold indicates the best performance while the underline indicates the second-best performance. Exist, Attr, Afford, Loc, Spatial, Count, Compar, Situated, Nav and Assist represent existence, attribute, affordance, location, spatial relationship, counting, comparison, situated reasoning, navigation, and assistance.