Abstract
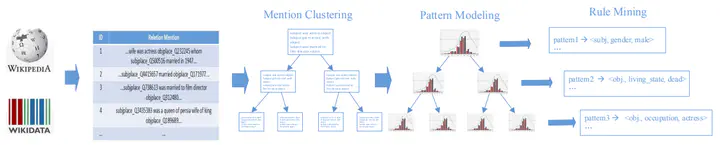
Knowledge bases (KBs), which are typical heterogeneous graphs that contain numerous triple facts of various types and relations, have shown remarkable advantages in many natural language processing (NLP) tasks. KBs usually integrate information from different sources such as human-edited online encyclopedias, news articles and even social networks. Due to the heterogeneous nature of these sources, both the KBs themselves and their applications on NLP tasks are far from perfect. On the one hand, KBs need further completion and refining to cover more knowledge with higher qualities. On the other hand, the joint modeling of structured knowledge in KBs and unstructured texts have not been well investigated. This paper proposes a novel natural language enhanced association rules mining (NEARM) framework to improve KBs. NEARM finds knowledge fragments from free texts in a data-driven manner. It first groups raw data (sentences) which contains related entity pairs into clusters of different granularities, and then integrates them with facts from KBs to mine rules in each clusters. To capture the relations between plain text and triple facts, NEARM produces rules that contain natural language patterns and/or triple facts in antecedent, and triple facts in consequent. In this way, NEARM can infer triple facts directly from plain text. At last, experiment results demonstrate the effectiveness of the NEARM on relation classification and triple facts reasoning.