Abstract
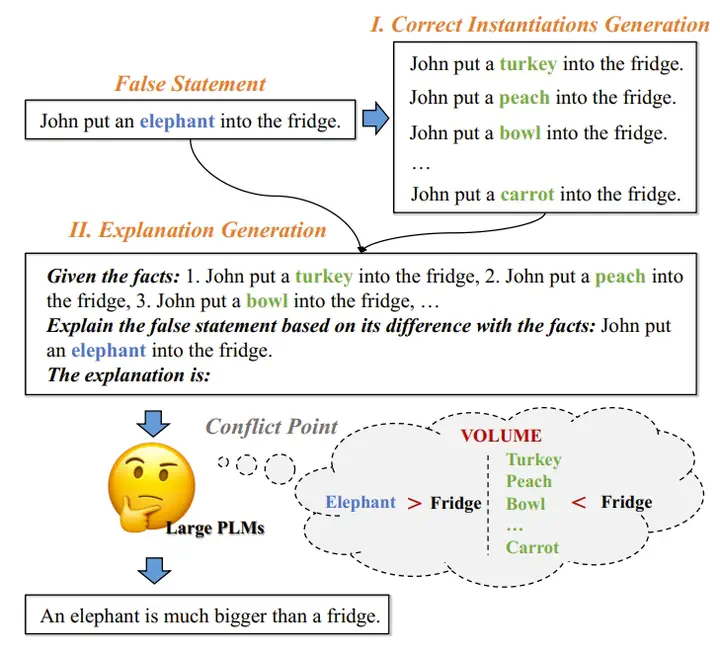
While large pre-trained language models (PLM) have shown their great skills at solving discriminative tasks, a significant gap remains when compared with humans for explanation-related tasks. Among them, explaining the reason why a statement is wrong (e.g., against commonsense) is incredibly challenging. The major difficulty is finding the conflict point, where the statement contradicts our real world. This paper proposes Neon, a two-phrase, unsupervised explanation generation framework. Neon first generates corrected instantiations of the statement (phase I), then uses them to prompt large PLMs to find the conflict point and complete the explanation (phase II). We conduct extensive experiments on two standard explanation benchmarks, i.e., ComVE and e-SNLI. According to both automatic and human evaluations, Neon outperforms baselines, even for those with human-annotated instantiations. In addition to explaining a negative prediction, we further demonstrate that Neon remains effective when generalizing to different scenarios.