Abstract
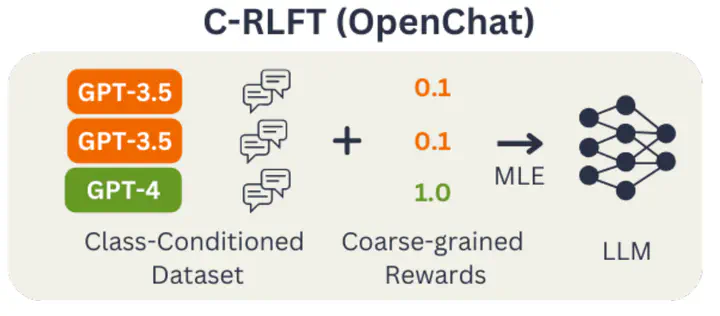
Nowadays, open-source large language models like LLaMA have emerged. Recent developments have incorporated supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to align these models with human goals. However, SFT methods treat all training data with mixed quality equally, while RLFT methods require high-quality pairwise or ranking-based preference data. In this study, we present a novel framework, named OpenChat, to advance open-source language models with mixed-quality data. Specifically, we consider the general SFT training data, consisting of a small amount of expert data mixed with a large proportion of sub-optimal data, without any preference labels. We propose the C(onditioned)-RLFT, which regards different data sources as coarse-grained reward labels and learns a class-conditioned policy to leverage complementary data quality information. Interestingly, the optimal policy in C-RLFT can be easily solved through single-stage, RL-free supervised learning, which is lightweight and avoids costly human preference labeling. Through extensive experiments on three standard benchmarks, our openchat-13b fine-tuned with C-RLFT achieves the highest average performance among all 13b open-source language models. Moreover, we use AGIEval to validate the model generalization performance, in which only openchat-13b surpasses the base model. Finally, we conduct a series of analyses to shed light on the effectiveness and robustness of OpenChat. Our code, data, and models are publicly available at https://github.com/imoneoi/openchat.